งานทดลองสุดสัปดาห์ที่ผ่านมา
เมื่อวานทดลองเขียน wrapper ครอบ Stanford Log-linear Part-Of-Speech Tagger ให้กลายเป็นปลั๊กอินสำหรับใช้กับ GATE (หลังจากตั้งท่ามานาน)
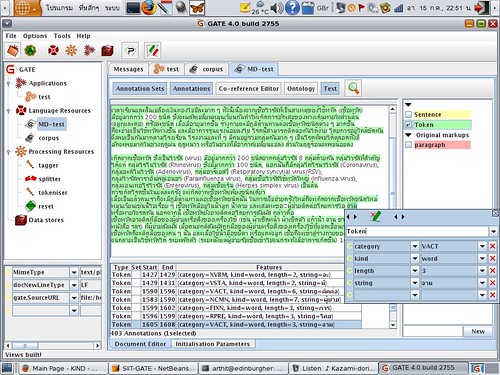
pipeline ในรูป มี 3 Processing Resources คือ tokensier, splitter และ tagger
tokensier คือ net.siit.gate.DictionaryBasedTokeniser เป็นตัวตัดคำธรรมดา ๆ ใช้พจนานุกรม1 และออกแบบให้ตัดได้คำที่ยาวที่สุด (longest-matching) ทำงานกับ AnnotationSet ของ GATE โดยตรง — จะสร้าง AnnotationSet ชื่อ “Token” ขึ้นมา
splitter คือ ANNIE Sentence Splitter เป็นตัวแบ่งประโยค โดยใช้กฎ (ภาษา JAPE เป็นลักษณะ regular expression over annotation) ตัวนี้มากับ GATE อยู่แล้ว และไม่ได้ออกแบบมาสำหรับภาษาไทย — เราเอามาใช้ไถ ๆ ไป เพื่อให้สร้าง AnnotationSet ชื่อ “Sentence” เท่านั้น (เป็นการ “สมมติว่ามี” จะได้ทดลองขั้นต่อไปได้)
tagger คือ net.siit.gate.StanfordPOSTagger เป็นตัวกำกับชนิดของคำ (Part-of-Speech) เป็น wrapper ไว้เรียกใช้/แปลงข้อมูลจาก edu.stanford.nlp.tagger.maxent.MaxentTagger ซึ่งเป็นตัวกำกับชนิดของคำแบบเรียนรู้จากชุดตัวอย่าง2 ตัว MaxentTagger จะรับข้อมูลเข้า/ส่งข้อมูลออกเป็น List<Sentence> ก็ต้องแปลงให้กลายเป็น AnnotationSet (เอาคำจากชุด “Token” โดยใช้ชุด “Sentence” ระบุขอบเขตประโยค3) เพื่อให้เข้ากับ GATE — ในขั้นตอนสร้าง List<Sentence> ตัว wrapper นี้ จะทึกทักเอาเองว่า Annotation ทั้งหมดใน AnnotationSet นั้น ไม่ทับซ้อนกัน (overlapping), ซึ่งจริง ๆ แล้ว ใน GATE นั้นอนุญาตให้ Annotation มันทับซ้อนกันได้ เช่น ถ้า Token ดันมีซ้อนกันเป็น [ab{cd]efg} แบบนี้ ตอนที่ตัว tagger (wrapper) แปลงเป็น Sentence จะได้ Sentence ที่บรรจุ Word = { "abcd", "cdefg" }
ทั้งหมดเป็น Java (ในส่วนที่พัฒนาเอง ใช้ NetBeans)
ทั้งหมดนี้ ไม่มีอะไรเป็น “ของใหม่” เป็นเพียงการทดลองหยิบชิ้นส่วนหรืออัลกอริธึมที่คนอื่นทำไว้แล้ว มาลองประกอบเข้าด้วยกันในกรอบ (framework) ของ GATE เท่านั้น (ส่วนที่มีเสริมเข้าไป ก็เพื่อให้ประกอบสนิทกันเท่านั้น)
แต่คาดหวังว่า การมีกรอบที่ชัดเจนแบบนี้ จะช่วยลดงานที่ไม่จำเป็นในการทดลอง/วิจัยในอนาคตไปได้บ้าง เพื่อจะได้มีเวลาไปเน้นเรื่อง “ใหม่ ๆ” จริง ๆ
1 สามารถระบุพจนานุกรมตอนสร้าง instance ใหม่ได้ ปัจจุบันคำส่วนหนึ่งมาจากคลังข้อมูลเอกสารการแพทย์ที่ KIND Lab, SIIT ทำร่วมกับ เภสัช ศิลปากร อีกส่วนหนึ่งมาจากตัวตัดคำ KU Wordcut ของเกษตร (สุธี สุดประเสริฐ), ใช้ Trie เป็นโครงสร้างข้อมูลขณะตัดคำ (org.speedblue.util.Trie)
2 ชุดตัวอย่างนำมาจากคลังข้อความ ORCHID โดยเนคเทค (ทดสอบแปลงข้อมูลโดยใช้สคริปต์ Groovy บน JVM)
3 จริง ๆ แล้ว เราสามารถใส่คำทั้งหมดเข้าไปประมวลผลทีเดียวได้ (คือมี 1 ประโยคใน List<Sentence> และทุกคำในเอกสารบรรจุอยู่ในประโยคนั้น) แต่การทำแบบนั้น คิดว่าน่าจะเปลืองหน่วยความจำ อีกเรื่องคือ ยังไม่ได้ศึกษาโดยละเอียดว่า ขอบเขตของประโยค มีส่วนต่อการคำนวณหาค่าความน่าจะเป็นในการกำกับชนิดของคำของคลาส MaxentTagger หรือไม่ (ตั้งสมมติฐานไว้ว่า น่าจะมี จึงพยายามแบ่งประโยค)
technorati tags:
GATE,
natural language processing,
Thai,
tagger
